数据清洗是对一些没有用的数据处理的过程
测试数据如下
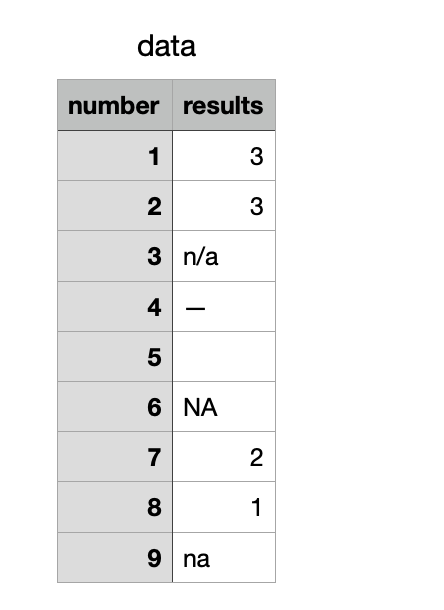
打印csv信息
import pandas as pd
df = pd.read_csv("data.csv")
print(df)
# 输出
number results
0 1 3
1 2 3
2 3 NaN
3 4 —
4 5 NaN
5 6 NaN
6 7 2
7 8 1
8 9 na可以看出,把NA ,n/a和空值显示为NaN
清洗空值
import pandas as pd
df = pd.read_csv("data.csv")
new_df = df.dropna()
print(new_df)
#输出
number results
0 1 3
1 2 3
3 4 —
6 7 2
7 8 1
8 9 naDataFrame.dropna(axis=0, how=’any’, thresh=None,subset=None, inplace=False)
axis: 0,逢空值剔除整行 ;1, 表示逢空值去掉整列
how: any,一行或一列有任何一个数据出现NA就去掉整行;all 一行或列都是NA才去掉这整行
thresh: 设置需要多少非空值的数据才可以保留下来
subset: 设置想要检查的列。如果是多个列,可以使用列名的list作为参数
inplace: 如果设置True,将计算得到的值直接覆盖之前的值并返回None,修改的是源数据通过isnull()判断各个单元格是否为空
import pandas as pd
df = pd.read_csv("data.csv")
print(df)
print(df['results'].isnull())
#输出
number results
0 1 3
1 2 3
2 3 NaN
3 4 —
4 5 NaN
5 6 NaN
6 7 2
7 8 1
8 9 na
0 False
1 False
2 True
3 False
4 True
5 True
6 False
7 False
8 False
Name: results, dtype: bool把na转换为空值
import pandas as pd
empty_values = ['na']
df = pd.read_csv('data.csv',na_values=empty_values)
print(df['results'])
#输出
0 3
1 3
2 NaN
3 —
4 NaN
5 NaN
6 2
7 1
8 NaN
Name: results, dtype: object默认情况下,dropna()方法返回一个新的DataFrame,不会修改源数据,如果要修改使用inplace=True参数
import pandas as pd
df = pd.read_csv('data.csv')
df.dropna(inplace=True)
print(df)移除某一列中有空值的行
import pandas as pd
df = pd.read_csv('data.csv')
df.dropna(subset=['results'],inplace=True)
print(df)使用fillna()方法替换空字段
import pandas as pd
df = pd.read_csv('data.csv')
df.fillna(555, inplace=True)指定列替换空字段
import pandas as pd
df = pd.read_csv('data.csv')
df['results'].fillna(555,inplace=True)
print(df)
#输出
number results
0 1 3
1 2 3
2 3 555
3 4 —
4 5 555
5 6 555
6 7 2
7 8 1
8 9 na列的均值 mean()、位数 median()、众数 mode()来替换空值
import pandas as pd
df = pd.read_csv('data.csv')
x = df['xxx'].mean()
df['xxx'].fillna(x,inplace = True)
print(df)pandas清洗格式错误数据
import pandas as pd
data = {
"Date": ['2022/10/01','2022/10/02','20221003'],
"Duration": [40, 45, 50]
}
df = pd.DataFrame(data, index=["day1","day2","day3"])
df['Date'] = pd.to_datetime(df['Date'])
print(df)
#输出
Date Duration
day1 2022-10-01 40
day2 2022-10-02 45
day3 2022-10-03 50pandas清洗错误数据
import pandas as pd
person = {
'name': ['wang', 'li', 'zhang'],
'age': [50, 40, 12345]
}
df = pd.DataFrame(person)
df.loc[2, 'age'] = 30
print(df)
#输出
name age
0 wang 50
1 li 40
2 zhang 30也可以设置条件语句
import pandas as pd
person = {
'name': ['wang', 'li', 'zhang'],
'age': [50, 150, 12345]
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x,'age'] > 120:
df.loc[x,'age'] = 120
print(df)
#输出
name age
0 wang 50
1 li 120
2 zhang 120
import pandas as pd
person = {
'name': ['wang', 'li', 'zhang'],
'age': [50, 150, 12345]
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x,'age'] > 120:
df.drop(x,inplace=True)
print(df)
#输出
name age
0 wang 50pandas清洗重复数据
如果数据是重复的duplicated()返回True,否则返回False
import pandas as pd
person = {
'name': ['wang', 'li', 'li', 'zhang'],
'age': [50, 150, 150, 12345]
}
df = pd.DataFrame(person)
print(df.duplicated())
#输出
0 False
1 False
2 True
3 False删除重复数据,使用duplicated()方法
import pandas as pd
person = {
'name': ['wang', 'li', 'li', 'zhang'],
'age': [50, 150, 150, 12345]
}
df = pd.DataFrame(person)
df.drop_duplicates(inplace=True)
print(df)
#输出
name age
0 wang 50
1 li 150
3 zhang 12345
0 Comments